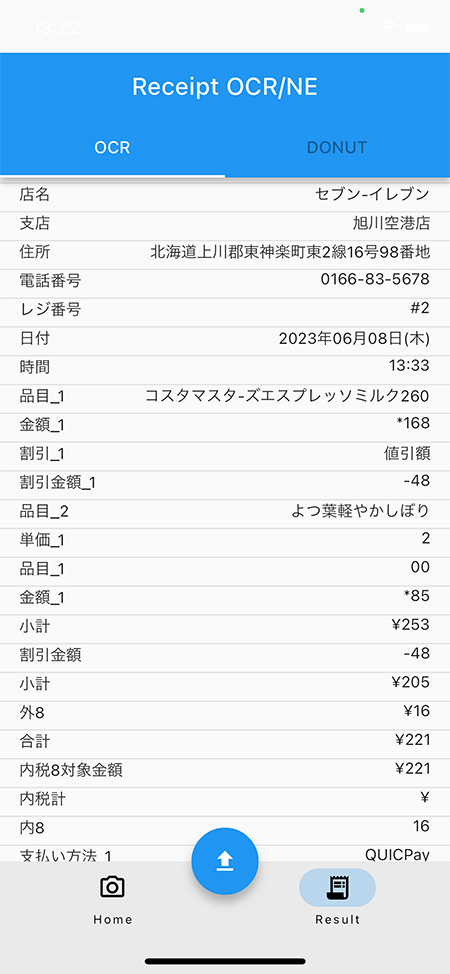
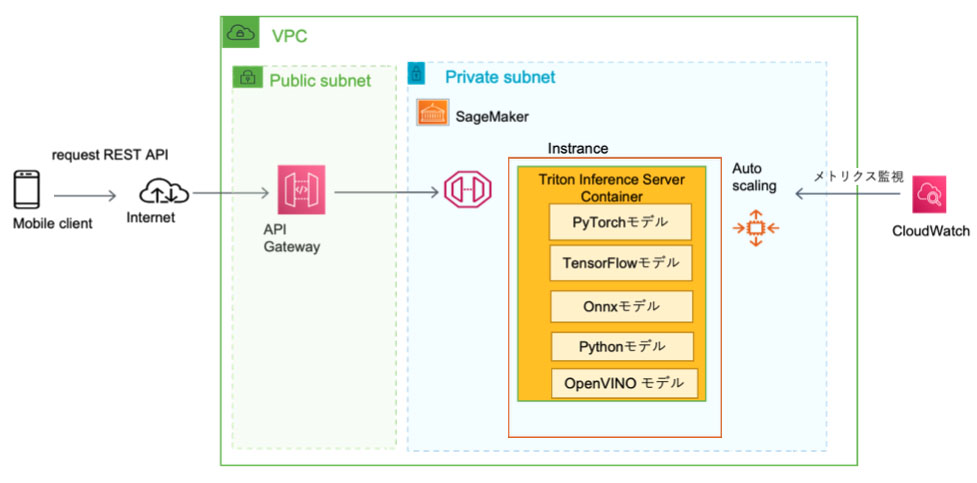
将来的には、Triton推論サーバをOpenVINO Model Serverで置き換え、Intelハードウェア上で動作するためのソフトウェア最適化を図ることも視野に入れています。特に、モデルの量子化とプルーニング、モデルのロードタイムの短縮、推論速度の高速化など、最新のOpenVINO 2023.0リリースにも大きな期待をしています。そのためには、既存のTensorFlowやPyTorchのモデルをすべてOpenVINOのモデルフォーマットに変換する必要がありますが、これについては今後詳しく書いていく予定ですので、その時はまたよろしくお願いします。