
- By BPR
- 0 comments
Japanese Receipt OCR and Named-entity Extraction: Low-cost Inference with Multiple Models using AWS SageMaker Serverless and Triton Inference Server
In this blog post I want to talk about how we deployed our server-based Optical Character Recognition (OCR) and Named-entity (NE) demo for extracting information from Japanese receipts. I think it’s a good demonstration of how to perform low-cost inference with multiple models, combining the best features of various different software technologies.
Our current OCR/NE demo service comprises two separate processing pipelines which run in parallel and are essentially independent of each other. One pipeline is a “conventional” OCR/NE cascade, and the other is a so-called end-to-end model which does all processing “in one go”.
In our conventional OCR/NE pipeline we have 4 different deep-learning models, each of which was trained from scratch, or fine-tuned, using TensorFlow:
- a model for detecting the corners of the central receipt in an image (in case there are multiple, visible receipts) and rectifying it to make it straight;
- a model for detecting the location of contiguous regions of text;
- an OCR model for recognizing the characters in each detected region of text; and
- an NE model, which is based on the BERT large language model (LLM), which takes all the text that was recognized in the image, sorts it from top-to-bottom and left-to-right, then classifies each character as belonging to one of several hundred different named entities of interest, such as address, date, shop name, and total amount etc.
While I refer to this pipeline as “conventional”, because it splits the information extraction task across several modules, it actually contains two novel components: namely (1) the receipt detection and rectification module, which we wrote about in detail here and (4) the NE model which operates at the text level and ignores explicit position information about where the text occurred originally in the image.
The other pipeline that runs in parallel, comprises an end-to-end model based on Donut, which is an encoder-decoder image transformer model that was pre-trained on a vast amount of synthetically generated textual image data, and which we fine-tuned using PyTorch to recognize the same set of named-entities as those used by our traditional pipeline. This approach is similar to the end-to-end receipt processing method that we described here.
To perform information extraction on actual receipts, we want to deploy this entire backend on the cheapest infrastructure available, since for the time being this system will only run as a demo. The demo should be responsive, but we don’t want it running constantly and thus incurring unnecessary running costs when it is not actually being used. Moreover, we also want to retain the option to deploy the same software seamlessly to an easily scalable server infrastructure with the absolute minimum of changes in future.
AWS SageMaker Serverless is perfect for this kind of use-case, since you are only charged for the total inference time that is incurred to process incoming requests. If there are no requests, then it doesn’t cost anything. There is also an incentive to process each request as quickly as possible, which means optimizing each component model to be as fast as possible. Moreover, when we are ready to deploy the system to run 24/7, we can easily migrate the same Docker images, that we build for AWS SageMaker Serverless, to AWS SageMaker Real-time Inference, or AWS SageMaker Asynchronous.
Having selected AWS SageMaker as our deployment target, we then need to decide what inference software to use to run on it. There are a number of options that AWS make available, including TensorFlow Serving, from Google, OpenVINO Model Server, from Intel, and Triton Inference Server, from Nvidia. As far as we are aware, only Triton Inference Server gives us the option of running different models, trained or converted to run under different model inference frameworks, within a single server instance. So, for now, we chose to run Triton Inference Server with the OpenVINO, ONNX, PyTorch, TensorFlow and Python model plugins.
We also developed a thin client in Flutter that allows the user to take a photo of a receipt within the app, or select one that is already saved in the camera roll on their PC or mobile device, as shown in the screenshot below:

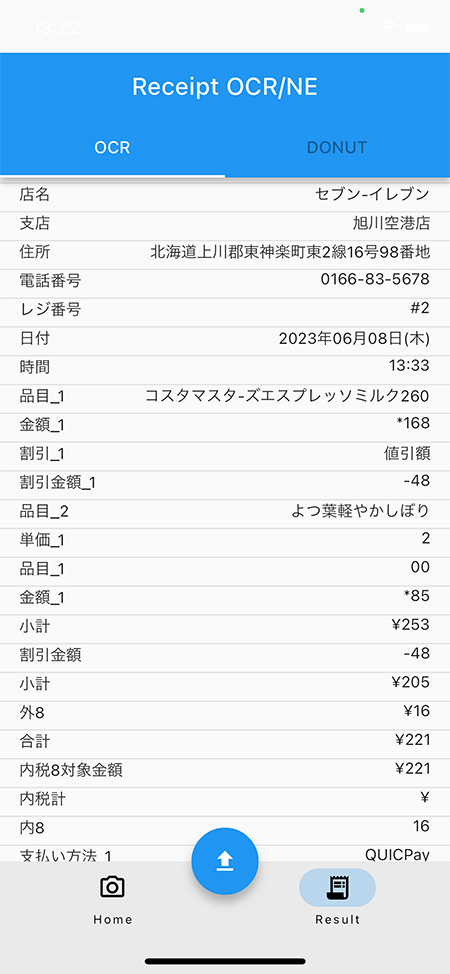
then send that image to our AWS SageMaker endpoint, which processes the image and then returns the results from the two different processing pipelines and displays them in the app, as shown in the following screenshot:
A high-level view of how all these different parts fit together is shown in the diagram below.
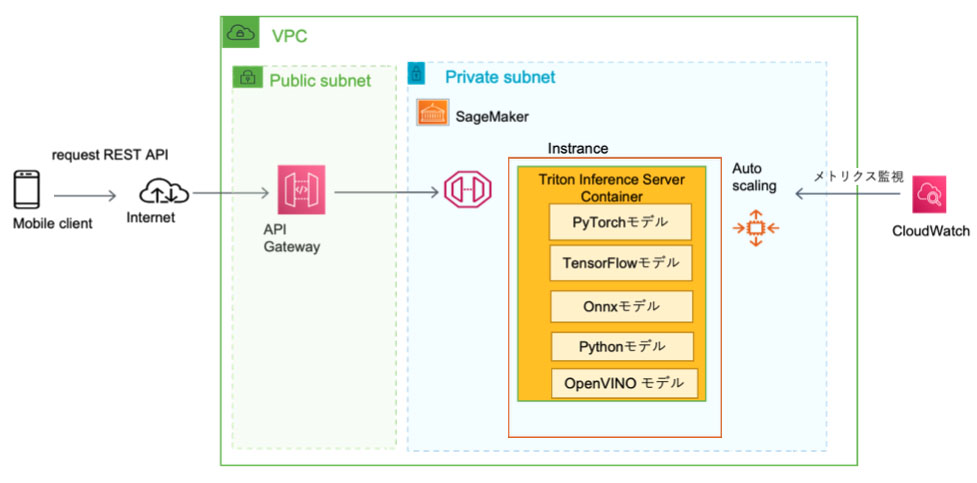
There were numerous issues that we encountered to get this whole system up and running smoothly. One such issue was getting Triton Inference Server to run on AWS SageMaker Serverless, which disables shared memory for security reasons by default. We managed to solve this by modifying the source code, re-compiling and re-building the Docker image.
Another issue was getting complex PyTorch models to run using the Triton Inference Server PyTorch plugin. Since the plugin uses the C++ API, rather than the Python API that is commonly used during model training, we first needed to separate the encoder and decoder components in Donut, trace each of them separately and save them to disk. They can then be read in and called through the PyTorch plugin’s C++ API with a separate call to the encoder, followed by a separate call to the decoder with the output of the encoder.
Both of the Donut encoder and decoder models are quite large at around 500Mb each, and the NE model is even larger at 800Mb. While we were able to successfully quantize the Donut encoder and decoder, we were not able to perform inference using these quantized models. This is something we are still looking at how to solve. However, we were able to successfully reduce the size of the NE model (recall that it is a BERT encoder-style LLM) by a factor of 4, after converting to ONNX and applying quantization. We then converted this quantized ONNX model to the OpenVINO format for use in the final system.
Inference speeds using the final system are approximately 1 second for our conventional pipeline and around 10 seconds for the end-to-end Donut pipeline. All models run simultaneously on a single AWS SageMaker Serverless instance with 6Gb RAM. Cold-start times (i.e. the time taken to copy model files from S3, boot up the serverless instance, and have it respond to requests are approximately 45 seconds. This means an initial request exceeds the maximum timeout of 30 seconds, but subsequent requests are almost instantaneous. We continue to work on reducing the cold-start time to avoid the initial timeout.
Future work will look at swapping out the Triton Inference Server with OpenVINO Model Server to take advantage of its software optimisations for running on Intel hardware. In particular, we also have high expectations for the latest OpenVINO 2023.0 release, which include model quantization and pruning, reduced model load-times and faster inference speeds. This will require us to convert all our existing TensorFlow and PyTorch models to the OpenVINO model format, which we plan to write more about in the future, so please do check back here then.
Keywords: TensorFlow, PyTorch, ONNX, OpenVINO, Triton Inference Server, AWS SageMaker, Serverless, Real-time Inference Server, client-server, OCR, NE, Japanese receipts
Tags:
blog_Search
Recent News
- AI-Assisted Penetration Testing
- Publication of the paper “Large Language Models for Named Entity Extraction and Spelling Correction”
- BEST PATH RESEARCH Exhibits at Intel Connection 2023
- Navit K.K. publishes an Interview with Best Path Research in “Sohos-Style”
- Publication of the paper “Automatic Detection and Rectification of Paper Receipts on Smartphones”